The Battle of the Data Platform.
Snowflake vs Databricks
For more 🚀
Check what I'm currently working on at Typedef.ai

The ‘00s started with the IPO of Salesforce in 2004. Salesforce, besides building what is currently considered the dominant CRM in the market, did something else potentially even more important:
it introduced SaaS software that was delivered over the Cloud.
That was huge because it allowed software to spread like a 🦠 and transform every possible industry. The impact was so great that in 2011, Marc Andreesen famously stated:
Software is eating the world.
Fast forward to 2019. There are still many industries to be disrupted, but the lunch is pretty much over. Technology has infiltrated every aspect of our lives, and platforms have been built for almost every function of a company. Just as in 2011, the current situation can be distilled into this quote from another famous person, Microsoft’s CEO Satya Nadella:
Today, every company is a software company. The change that has happened in the past 16-17 years is huge, and it cannot be described with a couple of quotes, no matter how accurate. But what’s even more fascinating today is that we also have a very good idea of what’s next.
This post is going to be about what the next big thing in tech in the ‘20s will be and which companies look like the main contenders.
💎 What’s the Next Big Thing?
First things first. What’s this next big thing we are talking about?
You can call it the Data Warehouse, the Data Lake, the Lake House, the Data Cloud, or any other term you come up with in the future. In the end, it’s all about the platform that will create value over data with accelerating velocity.
The companies that manage to do that will dominate the market in the same way that Salesforce, Google, and the rest have for the past 20 years, so the potential reward is huge.
Turning every business system, from computing infrastructure to CRMs and marketing platforms, into cloud software platforms allowed us not only to improve our work but also to turn every human process into an endless stream of data that can be stored and analyzed.
The next challenge is building on top of this data and delivering value in new ways that will have an impact comparable to or even greater than the revolution of software being delivered over the internet.
This new type of platform will need to have at least the following broad features:
🌪️ Allow the collection and consolidation of all data, regardless of structure or location.
💾 Store the data in a consistent, secure, elastic, accessible, and affordable way.
🧮 Allow the data to be analyzed so we can figure out what’s going on in our world.
👩 Allow the data to be processed into models that can offer predictive capabilities.
🚀 Expose the data to every possible consumer experience so we can act upon them and deliver value.
Delivering all the above is difficult, and these features might not all be delivered by one company. However, the company that builds the platform or product that delivers the most of these features will be the big winner.
I believe there are two companies that are closest to achieving this, but there is a third one that I will keep as a bonus for the end.
Let’s see who these companies are.
❄️Snowflake
I assume that everyone knows Snowflake. Even if you are not living in the tech bubble, their recent IPO got everyone talking about a database company. Snowflake’s IPO was the biggest software IPO ever and for a good reason—everyone is betting on the value that data will bring into the global economy in the next 10 years.
Snowflake started privately in 2012 and launched publicly in 2014. In only 6-8 years, the company was trading at a market cap of $96B, closing 2020 with ~$550M in revenue.
What’s more interesting than the current worth of the company is the evolution of their product. Their product path is clearly communicated in their S-1 filing, and this evolution gives us a glimpse of their ambition.
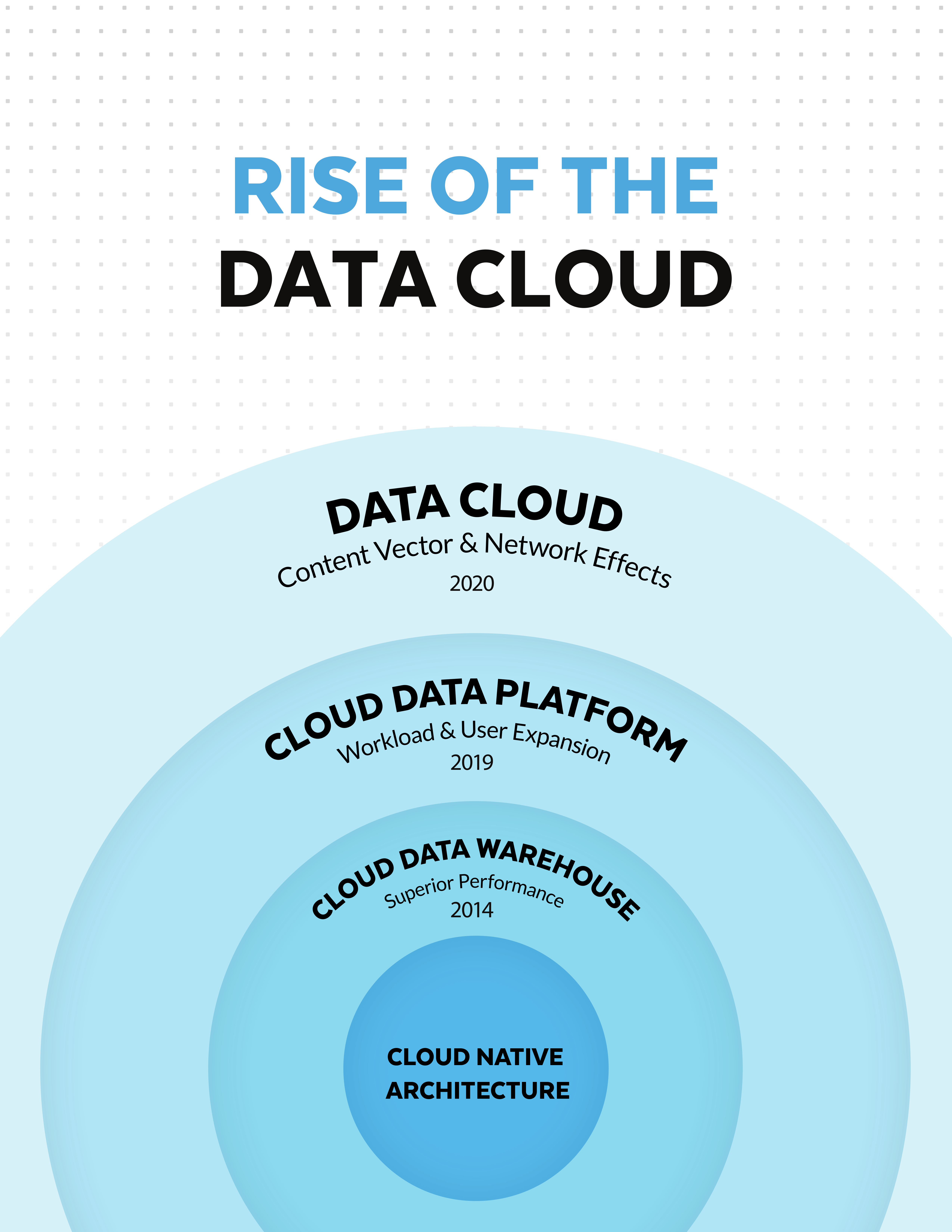
If you ask people today what Snowflake is, they would probably say that it’s a data warehouse. Snowflake has a different opinion though. The company started in 2014 by launching a Cloud Data Warehouse, but they quickly positioned the product as a cloud data platform and then as the Data Cloud.
Today Snowflake offers:
👉 A data warehouse 👉 A data lake 👉 A data marketplace 👉 External functions to build pipelines 👉 Snowsight, a visual interface for querying the data 👉 A data exchange to securely share data 👉 Snowpipe, for streaming data into Snowflake
A quick look at the above list reveals storage, sharing, streaming, ETL, and visualization functionality. Snowflake is much more than just a data warehouse today, and it only took them 6 years. Quite impressive.
🧱Databricks
Databricks was founded in 2013, just a year after Snowflake. However, Apache Spark, which Databricks is based on, started a bit earlier. Some of Databricks’ co-founders started Spark at UC Berkeley in 2009, and they made it open source in 2010. It wasn’t until 2013 that Spark became an Apache project.
Databricks has not yet gone public but has recently raised $1B in a Series-G round with the company valued at $28B. They closed 2020 with $425M in revenue.
To put things into perspective, Snowflake raised ~$500M a year before their IPO at a $12.4B valuation.
So in terms of performance on a high level, the companies are not that far away from each other.
Databricks also went through a very interesting product evolution. They started with Spark, but the amazingly talented team behind it didn’t get stuck just trying to monetize a successful open source project. Instead, they made R&D a big part of Databrick’s culture. Databricks today offers:
👉 A unified analytics platform for big data and ML. AKA Spark. 👉 SQL analytics on top of Spark. 👉 Delta Lake, a data lake which is closer to a data platform built on top of a data lake. 👉 Tight integration with Tensorflow and the ability to scale up TF on top of Spark. 👉 MLFlow. MLOps. 👉 Visualization. Redash. 👉 Happy Data Scientists and ML Engineers. R as first class citizen, collaborative notebooks, and ML runtime.
There are two noteworthy things about all the above. First, they have ETL support, BI, streaming processing and storage capabilities. And second, they make ML and Data Scientists first-class citizens in the Databricks ecosystem.
🧠 Product
It feels like the two products started on opposite sides of the spectrum, and now they are about to meet somewhere in the middle.
Databricks started with Spark, which was a reaction to how Map-Reduce was used on Hadoop. Map-Reduce was not only too low level but also difficult to develop and maintain. Spark fixed that with a new API. It also didn’t hurt that the introduction of RDDs and a better processing model tremendously improved the performance of data processing.
Spark started as an academic research project, was open sourced early on, and turned into an Apache project once the founders saw the opportunity to build a business around it.
Snowflake, on the other hand, had a very different start. The founders were working at Oracle when they saw the impact of cloud computing and figured out that the market was ready for a Cloud Data Warehouse. The development of Snowflake started in 2012, the same year that Amazon Redshift was initially released. These were the early days of the Cloud Data Warehouse era.
The founders of Snowflake saw a market opportunity first and then decided to build the technology.
The different origins of both companies have also impacted the user experience.
Databricks didn’t start as an easily manageable Cloud product. On the contrary, setting up and running Spark was quite a project, and if you wanted to scale and maintain it, the process required data engineers. Of course, this changed eventually. Today, Databricks offers a Cloud product that can be deployed on all the major Cloud providers.
To be fair, the way that Spark was deployed in the beginning made it a very good fit for large enterprises with on-prem requirements. Back then, K8s hadn’t been released yet (first release was in 2014), and the adoption of Cloud products among large enterprises wasn’t what it is today.
On the other hand, Snowflake was a Cloud-based product from day one. Spinning and scaling up data warehouses was and still is just a matter of a click. Virtual warehouses could be resized if necessary or put in sleep when they weren’t needed. Literally everyone with some basic knowledge of SQL could create a data warehouse, upload some data, and start executing queries.
This Cloud first approach, together with an amazing marketing machine and the option to separate storage from processing, skyrocketed the growth of Snowflake. This was especially true among small and medium sized companies. The numbers below speak for themselves:

Snowflake is clearly after the enterprise market, but they are just entering it. From their 3,000+ customers, only 56 can be considered large enterprises based on the revenue they contribute, with one of them (CapitalOne) responsible for 11% of Snowflake’s total revenue in 2020.
The product experience of each company also evolved from completely different starting points. Databricks started with everything that an enterprise needs and then continued building a product that could be used by a broader audience down market.
On the other side, Snowflake started with a SaaS Cloud experience, making it extremely easy to use for companies of any size, and later, they started adding enterprise related features while the enterprise market was beginning to embrace the Cloud.
Now let’s take a look at how their different approaches has impacted use cases for the products.
Snowflake’s first product was a Cloud Data Warehouse with all the characteristics that you would expect, like ACID transactions. BI is the typical workload for a data warehouse. The next step was to build a data lake. Both the separation of storage and computing and Snowflake’s excellent support for hierarchical data like JSON made this feasible.
As we mentioned earlier, Snowflake just released a new feature called Snowpark, which together with the support of unstructured data, allows data engineers and data scientists to execute ETL and ML related workloads.
In a way, Snowflake started from a much more rigid platform with very strong guarantees and ended up relaxing all these in order to allow the flexibility required by ML workloads.
On the other hand, Databricks started by providing a generic big data processing platform. There wasn’t any SQL at the beginning, but you could use the API to implement any logic you wanted.
This made the product ideal for ETL and ML workloads. SQL was introduced a bit later when we had MLFlow. Today, we have Delta Lake and the vision of the Lake House, which is a data lake with all the strict guarantees that a data warehouse traditionally offers.
As expected, Databricks started from a completely different angle. They started with a product that was as open as it could be and focused on processing that made it ideal for ETL and ML workloads.
Then, they moved to a Data Lake, and today, the company is promoting a new breed of data platform called the Lake House, which offers all the data consistency guarantees that a Data Warehouse traditionally had.
Here, we have a product path that started from the most flexible guarantees and evolved into a more rigid platform that can perform typical BI workloads.
At this point, I want to say something about one of the most advertised features of Snowflake, the separation of storage and processing.
Although Snowflake was the first Data Warehouse to implement such an architecture, Databricks and Spark were also following the same path, even if they didn’t emphasize it in the same way.
Actually, Databricks was assuming the storage layer, which at the beginning was something like HDFS. Databricks was the processing, and it was separated from storage.
I’m assuming that both companies got that right from the beginning, but Snowflake did a much better job at marketing this.
In terms of the evolution of the persona that the two products address, I don’t have much to say, as they just follow the use cases and they are straightforward enough to imagine.
What I believe is worth mentioning though, is that Databricks, especially at the beginning, was requiring a special type of data engineer to operate the product—a kind of hybrid between a data engineer and a system engineer.
That was natural because of the nature of the initial product. I assume that has changed a lot since the introduction of the Cloud product.
Snowflake, on the other hand, can be operated in small teams without a data engineer. This probably isn’t very efficient, but it is improving as they introduce features like Snowpark.
Some Final Thoughts on Product
It’s clear that the two companies have created some pretty amazing products. They both definitely have to keep executing on their product roadmaps to win this, but what are the strengths of each one?
Considering both what we’ve talked about so far and the founding teams of each company, Snowflake excels in ruthless execution, and Databricks excels in innovation.
However, this doesn’t mean that Snowflake is not capable of innovating or that Databricks cannot execute. You can’t build companies valued in the tens of billions without doing both.
It remains to be seen who’s going to win the product battle, but regardless of the result, both companies are going to create some exciting new technology.
📈Marketing
(I’ve learned a lot for this section from an excellent post by Lars Kamp. It’s worth taking the time to read it, and you can find it here)
Snowflake
The first thing that someone notices about Snowflake marketing is the branding. This is extremely rare for technology companies that build databases. Just check the tweet they posted to celebrate the GA of the product.

If it’s not your first time hearing about Snowflake, you have probably heard about their famous billboards on 101 On a daily basis, thousands of people were exposed to the brand, and for something as dry as a database, making the product so accessible was a very successful approach.
It’s clear that for Snowflake, building the brand was at least as important as the product itself, and I’d say that this strategy paid off in the end. We all have something to learn from Snowflake when it comes to building a brand for a technology product.
There’s another important piece in the brand of Snowflake: the current CEO Frank Slootman. Snowflake is his third IPO, and having three IPOs under your belt is an impressive accomplishment. The respect Slootman has earned and his personality have both boosted the brand even further. Snowflake’s obsession on brand even affected their process of finding a CEO to take the company public.
We mentioned before that one of Snowflake’s key strengths is ruthless execution. This is also true in marketing.
Snowflake didn’t only invest in branding; they also designed and executed a sophisticated ABM (Account Based Management) strategy. Building the volume of personalized content necessary to attract your leads and make your ABM strategy successful requires a lot of dedication and focus. (Learn more about this from Lars here)
In addition to ABM, Snowflake also excels in word-of-mouth marketing. Because the company aims to deliver a good product experience, customers are more likely to share their stories about using Snowflake.
The final piece of Snowflake’s marketing engine that I’d like to talk about is their ability to create hype. Hype is built on top of the foundations we mentioned earlier: the right people, the right branding, and the right marketing tactics.
Snowflake has put all of those together, and that’s an amazing achievement. The fact that they have embedded themselves in the market’s consciousness for revolutionizing the industry by separating storage and computing is also a testament to their ability to create hype.
All the above are ultra-boosted by the most successful IPO in the history of the software industry and by all the money that comes from that IPO.
Let’s see what Databricks has to compete against Snowflake’s marketing juggernaut.
Databricks
Databricks has a different approach to marketing, but judging by the result, it has worked well for them.
One of the most important aspects of Databrick’s marketing is their open source nature, which can be an amazing moat if leveraged correctly.
Databricks built their brand on top of Spark, which is an Apache project, and honestly, I don’t think there’s an engineer out there who doesn’t know it or hasn’t at least tried it at some point. The developer community that has been built around Spark has not only helped them create a strong brand and network effects but has also given them a way to set foot inside large enterprises.
Today, the Apache Spark repository has almost 29K stars on Github, 1,617 contributors, and an amazing 23.3K forks. To put this in perspective, the Golang repo has 11.9K forks, the linux kernel has 37.5K, and React has 32.7K.
Databricks’ adoption of OSS has also allowed them to use education to generate leads through the Databricks Academy. Education has successfully been used as a marketing tool a few times in OSS. For example, RedisLabs has a similar program. Databricks also has about 40K subscribers on Youtube for their videos; that’s an impressive number for such a technical product.
Certification and education programs are easier to implement with open source projects because people feel that the time they spent getting the certification is not linked to a specific company and that they can use the acquired skills in a more general setting.
Keep in mind that education can also add virality and network effects, which is why Databricks invests so heavily in it.
Open source products and strong personalities usually go together, and this is also true for Spark and Databricks. Just as Snowflake capitalizes on their CEO, Databricks capitalizes heavily on its founders, especially in the dev and open source community.
The founders have a strong academic background, and they are well respected in the developer community for their unique contributions to the industry—both their academic papers and their decision to make Spark open source.
Authority is important among developers and engineers, and Databricks has a lot of it. That’s another strong moat for Databricks.
Finally, Databricks is going after the large enterprises, and thus, they are implementing marketing tactics that are common in this space, like events. I’m not going to expand much on that as the whole point of this article is to identify the unique strengths that each company has. Databricks is executing extremely well on this too, but it won’t be difficult for Snowflake to catch up.
Some Final Thoughts on Marketing
The two companies are very different in the way they approach marketing, but both have managed to create some unique strengths.
For Snowflake, branding is their strength. From day one, they have always made sure to keep boosting their brand even further. The current brand, together with the money the IPO brought, will create a formidable marketing engine.
As they go upmarket though, it remains to be seen how the brand will resonate among the large enterprises.
On the other hand, Databricks has played the open source strategy very successfully. They have managed to position the product amazingly well and to make it one of the most recognizable names in the space.
Developers love it, they know how to use it, and they have invested in learning it.
That’s very hard to beat. In addition, Databricks has already figured out how to craft a narrative that works in the enterprise market, but it remains to be seen if what they have created will survive the Snowflake attack.
It’s interesting to note here that both companies are expanding in opposite directions, and they will probably face each other in different markets too.
Databricks is trying to go after the mid-market, where Snowflake dominates, while Snowflake is trying to go up-market, where Databricks has a very strong presence.
I’m very excited to see how their strategies and tactics will work against each other while they are going after different market segments.
🕴️Go to Market
A good product and marketing do not suffice, especially if you are after the growth trajectories that Silicon Valley is famous for. Let’s see how the two companies have achieved their growth and how this will position them against each other in dominating the market for the data platform.
Snowflake
Snowflake has achieved some amazing growth. In their S-1 filing, they report a 121% revenue growth Q2 YoY with a 158% Net Retention (more on that later). For a company that sells database software, these are some remarkable numbers. So how did they do it?
In my opinion there are three pillars to their success:
💲The way they used cloud marketplaces, especially from AWS. 💲The way they used their partner network. 💲The structure of their pricing.
Snowflake’s most well-known strategy is how they used the AWS marketplace to boost their sales. AWS incentivizes their account executives to deliver maximum value to their customers, even if they end up selling competitive products.
Because of the superior experience that Snowflake offered, customers were happier and were spending more. As a consequence, AWS reps were hitting their marketplace quotas and giving Snowflake new customers. In a way, Snowflake was using AWS reps to sell their product.
This allowed Snowflake to grow much faster than they could with their own sales force, while accessing leads that AWS actually paid to acquire.
The second important strategy is how Snowflake built partnerships.
A database cannot offer much value without data. Visualization and BI tools are also important, but even with those, you still need the data. Early on, Snowflake partnered with vendors like Looker and Fivetran.
The situation was a win-win. Snowflake could demonstrate the value of its product quickly, while the BI tools and the data pipelines got leads and closed more deals.
But it doesn’t end there. When data pipelines and BI tools got commoditized, prices for these tools went down, and because they are natural complements to a data warehouse, demand for Snowflake went up.
The last strategy is pricing. Snowflake aggressively pushed the concept of separating storage and computing, which lowers costs and has the benefit of scale.
Snowflake also implemented a “pay as you go” or usage-based model. You pay separately for the storage you use and the computing you perform based on a credit system. Finally, you didn’t have to pay upfront like AWS required at the time.
These combined features gave the customer the impression that they have total control over spending and that the product is cheaper, especially at the beginning.
This made small and medium sized companies more likely to invest in a scalable data warehouse solution, even if they didn’t need one.
With Snowflake, a customer starts paying on a monthly basis. As the volume starts rising, reps will reach out and offer a yearly contract with a discount and the promise that unused volume will roll over into the next usage term.
The combination of the discount, the safety of keeping the volume for the next term, and the obscurity of the pricing, makes it extremely easy to spend more than expected on the product. Include with this the physical tendency of data volume to increase, and you have an amazing engine that can report a 158% net retention.
Databricks
It’s more difficult to find out what Databricks is doing because it’s not a public company yet, but we can infer some things, although with less confidence than with Snowflake. It should be enough for a high level comparison, though.
Databricks is an enterprise sales company, so their jobs page is very revealing.
There’s an obvious focus on Enterprise sales, especially compared to mid-market.
In addition to Enterprise Account Executives, Databricks is also investing heavily in recruiting Solution Architects. It looks like they are executing a standard enterprise sales playbook, where solution architects customize and propose architectures while AEs are closing the deals in parallel. This is similar to what AWS is doing.
This makes total sense for a company like Databricks. Large enterprises have very unique needs and requirements, so customization is pretty much standard. This playbook is a good choice because the technology space is still very new; ML and AI have only been around for less than 3 years.
A good question here is how Databricks plans to adapt this playbook in the mid-market. Based on their careers page, it seems that they are investing in a Customer Success organization and hiring both CS executives and CS Engineers. It seems like they are adapting the enterprise playbook for the mid-market.
This choice is probably the safest, considering the culture of the company. They are not radically changing the way they interact with customers but are focusing on how they can scale interactions down/up based on the type of customer.
It’s obvious that Databricks knows how to play the Enterprise game and that most importantly, they have built relationships that are crucial for selling in the enterprise space. This playbook is also supported by open source.
The open source project allows Databricks to enter organizations in a bottom-up way too. Engineers get exposed to the product, educate themselves on it, and in some cases, even introduce it into production before Databricks starts the sales cycle.
At the same time, open source also adds credibility and reduces the perceived risk for large enterprises. If something goes wrong with Databricks, the software and the trained engineers will be there to take care of the infrastructure.
Databricks has built an amazing machine to attack the large enterprise space from both angles, and based on the numbers they have shared so far, this is paying off.
Databricks started their partnership program much later in their lifecycle than Snowflake. Databricks has a number of technology partners but a lot more system integrator partners, so investing more on the second group makes sense for them.
Databricks offers a highly customizable product that requires good architecture to introduce it into an organization. They are catching up in creating a technology ecosystem, but it’s definitely harder for them than for Snowflake.
There’s another type of partnership that is not advertised on the website, which I believe is especially important for Databricks—partnerships with Cloud providers, like Google and Amazon. Considering their focus on the enterprise market and how early they deployed on Azure, my suspicion is that Databricks is working closely with Microsoft, but I cannot verify that.
Databricks also introduced a cloud offering, although it’s probably still evolving as a product. The pricing model is similar to what Snowflake has: you buy credits and based on where the infrastructure is deployed and how the resources are used, you consume different amounts of credits. There are a couple of things that I don’t know though:
💲How much revenue comes from the cloud business. 💲What’s the net retention. 💲How sales is implementing expansion on the cloud accounts.
Final Thoughts on Go to Market
The go-to-market strategies employed by the two companies, in particular the markets they decided to attack first, are representative of where each company comes from.
There’s no doubt though that the two companies will fight for market share in the large enterprise market. That’s where the data and the money are.
My feeling is that Databricks has at least a small advantage here. Their established enterprise sales playbook, their relationships, and their open source advantage increases the stickiness of the product by a lot.
Snowflake has an amazing marketing machine that is optimized for the mid-market. It also has a lot of momentum and money from the current IPO. If Snowflake wants to keep growing, it will have to go after the enterprise market. It remains to be seen how they will do that.
If I had to guess, I’d say that Snowflake will try to get into large enterprises by positioning their product as supplementary to Databricks. After all, selling to a team inside a big organization is not that different from selling to mid-market. After Snowflake lands inside the company, the war of the AEs can start.

It’s Not Just Snowflake and Databricks
We focused on the two main contenders because they have a clear vision, they execute well, they are growing fast, and the financial markets have put money on them. But there are more amazing companies out there that might surprise us in the end. I’ll quickly go through two of them that I find extremely interesting.
Confluent
Confluent is a bit of a mystery to me. In a way, they look very similar to Databricks.
⚡Open source with huge community. ⚡Defined a whole category around stream processing with Kafka. ⚡Enterprise adoption. ⚡Cloud offering today.
I suppose that they could even follow the same playbooks in terms of go-to-market and marketing.
That said, it doesn’t feel like Confluent is at the same pace as Databricks and Snowflake in delivering the Cloud Data Platform.
I’m not sure why this is the case, but one guess is that they are being left behind in creating this new category, both in terms of product and positioning.
While Databricks and Snowflake are leaving the concept of the database behind and trying to educate the world on the data cloud and the lake house, Confluent is trying to convince people that Kafka can be a database.
I won’t argue that being a database is important in realizing this new platform (after all, Delta Lake is an attempt to bring database features to the lake and cloud object storage), but it’s also important to communicate a vision that is broader than what the term database can communicate.
Nevertheless, I’m really curious to see what Confluent will come up with. They are innovators. They have built a strong business, and I’d love to see their solution in realizing the dream of the Cloud Data Platform.
Dremio
Dremio is a younger company compared to the rest we have covered so far. But in some ways, they are equally impressive.
Dremio is a Data Lake product, offering a solution closer to Delta Lake. They have raised $265M so far, with a Series D being their latest funding round. They also have a very interesting relationship with open source.
Although there’s no specific open source project associated with them with the hype of Spark or Kafka, they are very actively supporting some interesting projects:
💾 Apache Arrow 💾 Apache Arrow Flight 💾 Apache Iceberg 💾 “donated” Gandiva to Apache Arrow.
What we see with the above projects is that, although Dremio does not own the killer open source project that others have, they support some very strategic open source initiatives—specifically, anything that has to do with open sourcing core components of an RDBMS, things like storage with Iceberg, in-memory columnar representation with Arrow, and JIT execution of queries based on LLVM.
If their plan works, I think it might turn into something big. Making available the core components of an RDBMS, so that more people can use them to build data infrastructure products, could help them commoditize parts of the stack and put them in a powerful position, similar to how things worked for Snowflake with the data pipelines.
I’m very excited about all the tools mentioned here and even more excited to see what Dremio will be able to achieve with their strategy.
Final Thoughts
Watching these companies fight for ownership of the data cloud is fascinating, at least for me. It’s amazing to watch how complex technology is built and productized in order to build these massive, hyper-growth companies.
We are just at the beginning of the journey, and regardless of who wins, I can’t wait to see what new technologies will be created and what business lessons we will learn in the next 10 years.
Check what I'm currently working on at Typedef.ai