Snowflake Streaming Ingestion.
How Streaming Data Can be Ingested in Snowflake.
For more 🚀
Check what I'm currently working on at Typedef.ai
Snowflake Streaming
Snowflake is investing heavily in improving the experience of building streaming pipelines.
Let’s see how you can work with streaming data today on snowflake and what are some of the upcoming new features that are either rumored or announced already.
Streaming to batch
This is the most basic type of pipeline someone can build to load streaming data into Snowflake.
It assumes that the data are landed on S3 somehow and from there, the Data Engineer adds standard batch loading logic to the pipeline to ingest the data into Snowflake.
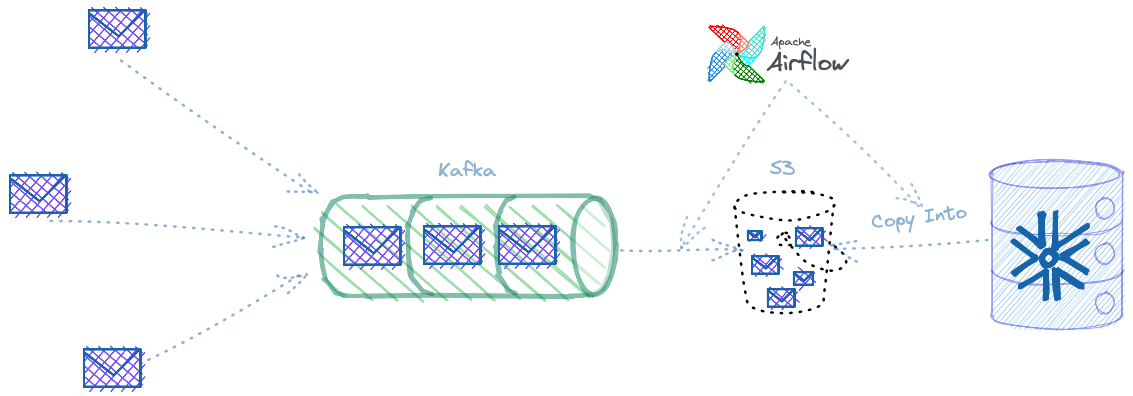
Ingesting Streaming data into Snowflake, the Batch way
The above diagram presents in a simplified way, how someone can ingest streaming data into Snowflake, assuming the standard batch ingestion that Snowflake supports.
Data is pushed into a Kafka topic, from there the data has to land on S3 and after this is done, a COPY INTO command can be used from within Snowflake to ingest the data into tables.
To get the data from Kafka to S3, you can use Kafka Connect S3 Sink. There are a couple of considerations about the Kafka Connect S3 Sink.
First, you need to decide the format the data will be serialized to. Out of the box Kafka Connect supports JSON and Avro. Both are supported by Snowflake but there are other options too. For example, Parquet is officially supported as an output format for some time now.
Kafka Considerations
What is important to consider here is the support for schema by the format you choose. With the formats that support schema (Parquet, Avro, ORC), Snowflake can automatically detect it and use it to import the data. Choose wisely!
another consideration is how the data will be partitioned. That’s a bit more complicated of a decision and it might change as your workload characteristics change, but let’s see the standard options Kafka Connect offers for partitioning.
There are three default partitioners available:
- Kafka Partitions → You partition based on what partitioning has been configured on your Kafka topic.
- Field Partitions → Self-explanatory I guess, partitioning happens based on a field’s value, e.g. based on user_id or country_name.
- Time Partitions → In days and hours. Again self-explanatory I hope but to give an example, if you partition on hours, then you’ll get 24 partitions for each day.
It is possible to extend the time based partitioner and create your own, e.g. you want to partition per minute for some reason. You can also create your own partitioner in general by implementing the appropriate interfaces, in case you want something more sophisticated.
Snowflake Considerations
After the data is available on S3, the Data Engineer can simply ingest the data in the same way that would do with any other bulk imported data. There’s nothing special with the data coming from Kafka or being streaming in nature, actually by landing the data into S3 we just turned the data from a stream of data in motion to a bulk of data at rest!
Overall Considerations
There’s one part of the diagram I didn’t mention so far, that’s Airflow and it’s an important one. To ensure the proper operation of pipelines built in this way, coordination is required and for that you need something like Airflow.
Practically you need to know when enough data has landed from your Kafka topic to your S3 buckets and then execute a bulk load task, when and if this is successful, go back and check again on S3 for new data. Repeat ad infinitum.
What happens when the data in your topic change in schema? How do you implement policies for schema conflicts and resolution?
If you adopt a dead letter queue approach, how do you process the data in it and how do you re-ingest if you have to?
Finally, how do you handle latency? The whole point of working with data already in motion is that you can have great latency benefits, make the data available to the user much faster than in the case of bulk ingestion. But the whole process we introduce here will set some pretty strict lower bounds to the latency you can deliver.
Snowpipe
Snowflake, understanding the limitations of the previous model and the value of working with streaming data, came up with Snowpipe.
How does Snowpipe improve the previous model? In a way, what Snowpipe does is to remove the need for manually having to import the data into the warehouse using the typical bulk ingestion process. At the same time, it removes the reliance on the external scheduler/coordinator because Snowpipe runs behind the scenes and doesn’t require someone to trigger it. But let’s get into more details on what Snowpipe actually does.
Snowpipe Considerations
How is Snowpipe different? First of all, we should say that the way Snowpipe works is commonly referred as micro-batching.
By micro-batching, people mean that there’s a process that is actually performing batch inserts, but the batches are small enough and the inserts frequent enough, that we get closer to streaming ingestion experience.
Snowpipe still requires the data to be staged on S3, it operates after the data has been landed off the Kafka topic and automates the process of getting the data into Snowflake. For how you can get the data there check Kafka Considerations.
COPY is still used in a way, actually a COPY statement is defined as part of setting up your Snowpipe. There you define where the data is staged and where you want the data to be inserted in Snowflake.
Snowpipe is a service which after you create a new pipe, keeps observing the staging area for new data. As soon as new data has been detected, the pipe will be executed and the service will attempt to ingest the data into Snowflake.
How Snowpipe differs from bulk ingestion though?
Snowpipe Vs Bulk Ingest
First, Snowpipe does not require a virtual warehouse to be running for ingesting the data. In the bulk case, a data warehouse has to be active and the user executed the COPY command in it. Snowpipe on the other hand is a service that runs independently of your warehouses.
Is this a good thing? I’d say yes it is. Ingestion is primarily an IO heavy operation, data warehouses are optimized to offer a balance between IO and Compute. You can think of a Snowpipe service as a warehouse optimized for ingestion. In this way you let Snowflake figure out how to better use resources for this particular job.
It helps you manage your warehouses better by separating ingestion from analytical and processing workloads. In this way you can focus on your SLAs and don’t worry about the unpredictability of a streaming ingestion happening in parallel.
It also separates costs as Snowpipe is priced separately.
Another difference is how the two approaches handle transactions. In a bulk ingestion pipeline you can ingest all your data in one transaction. With Snowpipe and micro-batching, each micro-batch is inserted inside one transaction.
Is this a good or bad thing? I’d say it depends on your workload but transaction semantics are very different when we think in terms of unbounded streams of data anyway. In any case, you have to make sure you understand how transactions will work in your specific scenario.
There are a couple other differences that I find less interesting but I’d encourage you to check the documentation of Snowpipe, it has a great section describing the difference between the two ingestion approaches.
Latency
So what’s the difference in terms of latency when we use Snowpipe?
It is difficult to estimate the latency of Snowpipe as it depends on many parameters like partitioning, file formats, if transformations are included in the COPY statements and others.
For this reason, the best thing to do is to experiment with your workloads and measure the latency to at least get a baseline and then make sure you keep monitoring the pipelines as you operate them.
Anecdotally, you can achieve latencies of around 2-3 minutes with Snowpipe, where by latency here we mean the time between the moment the data lands on S3 and when it becomes available on your Snowflake tables for querying.
The Future
Snowflake knows that bridging the gap between streaming and batch ingestion will just make their customers happier and they plan to do that. Some of the stuff that we will soon see on Snowflake.
“True” Streaming ingestion. By that we mean a service that will offer an interface, probably REST, that will allow the user to ingest data on a row level instead of the file based approach Snowpipe supports now. This service needs to support low latency, ordered and low latency ingestion at the row level.
The question here is how this service can scale to extreme scale without requiring by the user to fine tune it?
For the above service to be even more valuable and offer lower latencies, Snowflake needs to support ingesting data directly from a Kafka topic and thus eliminate the need to stage the data on S3 first.
This is important not just from a latency perspective but also from a user experience perspective. Having to maintain a separated infrastructure to land the data from Kafka to S3 and deal with all the complexity and issues that this entails, is big part of what makes streaming data hard to work with.
Finally, the journey of the data does not end with it being ingested, on the contrary that’s exactly when the journey begins. So, how can the user define not just where the data should land, but also what happens next?
That’s what a new feature named Dynamic Tables is addressing. What are they?
- Declarative pipelines. You just describe what you want, Snowflake figures out how to build it.
- Incremental Updates. New data arrives, we don’t have to recalculate everything.
- Snapshot Isolation. Remember what we said earlier about transactions?
- Automatic Refreshes. You don’t have to go and trigger a refresh, Snowflake will do that for you.
- Materialization. Data is materialized for greater performance and lower latencies.
- Support for any query. Materialized views on Snowflake were pretty limited in terms of what SQL you could use to define them (e.g. no joins.)
As you can see, streaming ingestion is just the first part of a customer journey with many different features that can change completely the way people build and maintain data infrastructure today.
Can’t wait to see what Snowflake delivers and how it will shape the market expectations on working with data warehouses.
Check what I'm currently working on at Typedef.ai