MLOps is Mostly Data Engineering.
The overlap between MLOps and Data Engineering
For more 🚀
MLOps is Mostly Data Engineering
Introduction
MLOps is a relatively recent term. A quick search on Google Trends reveals that the term started being searched for, around the end of 2019.
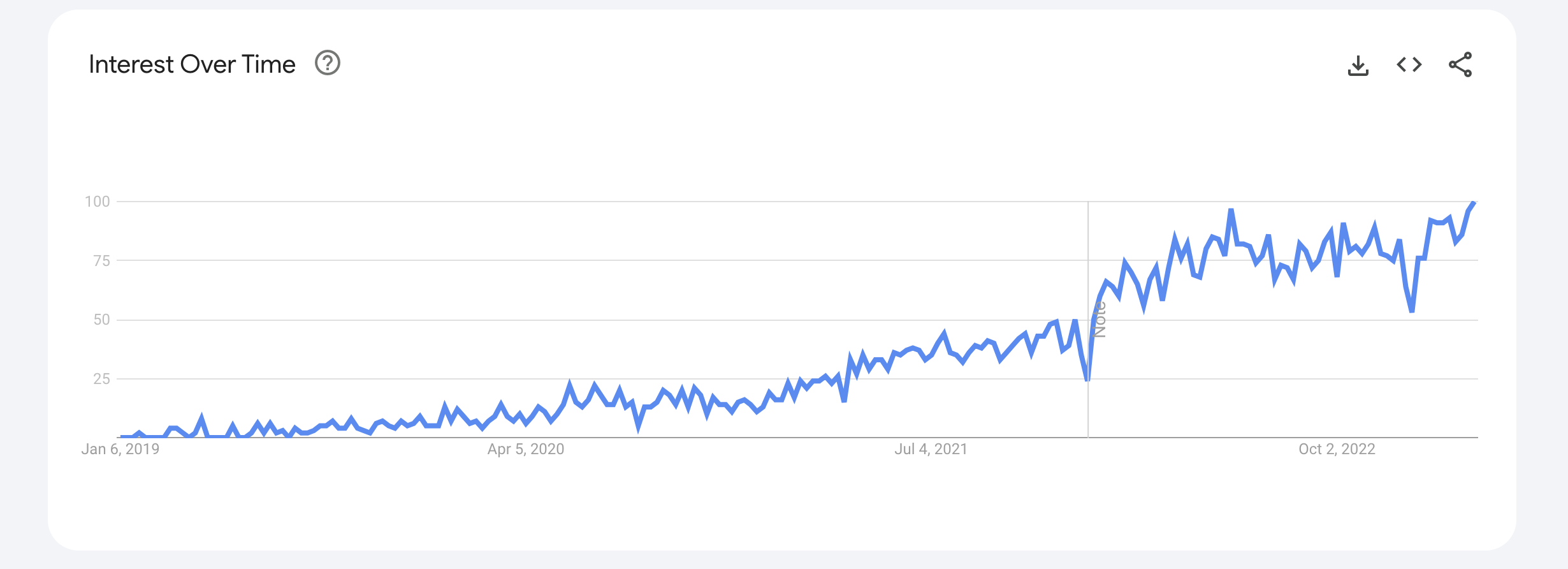
Upon examining the trend line above, we can observe a significant spike that occurred at the end of 2021. Since then, the interest has remained high.
ML is not something new though, if we check Google Trends for that term, we will see that the term exists since 2004 and with the interest growing exponentially, since 2015.
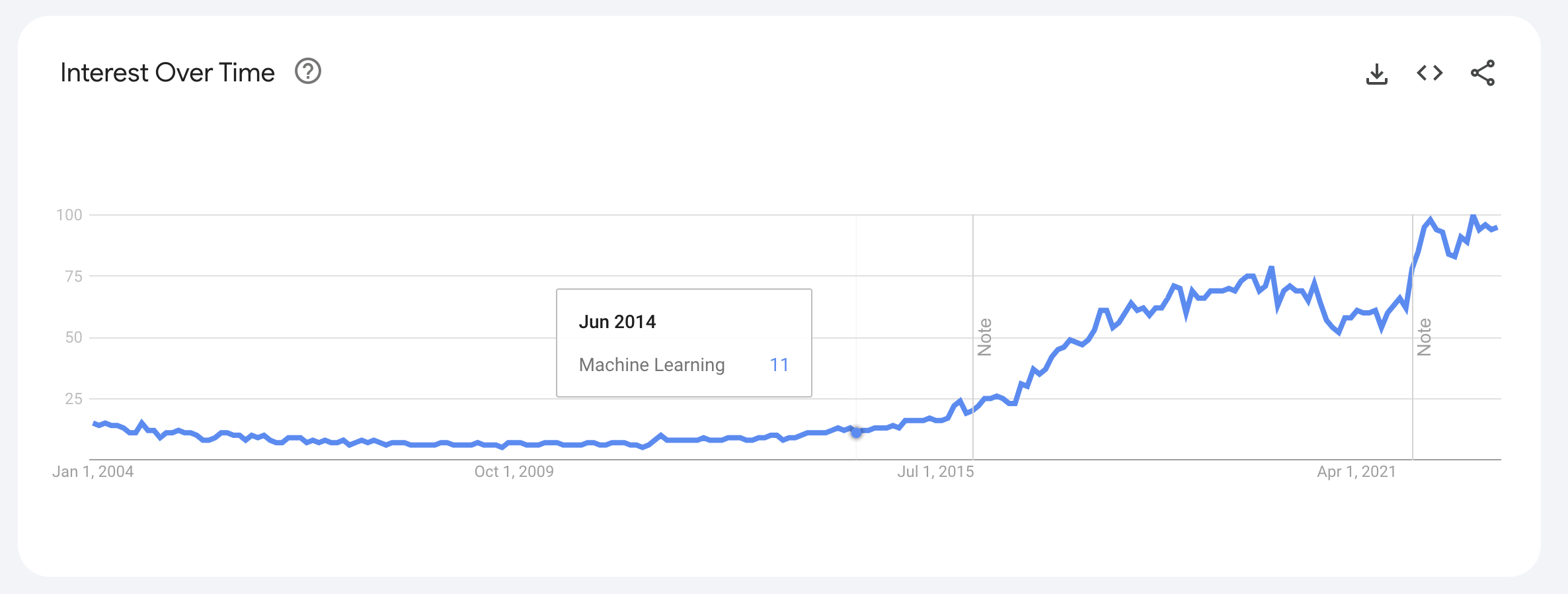 Interest Over Time for the term Machine Learning on Google
Interest Over Time for the term Machine Learning on Google
Machine learning has made amazing progress in the past 10 years, with some of the most important achievements in tech being related to it.
The rapid growth of machine learning is what sparked the creation of MLOps as a category. With the pace of innovation around ML accelerating, teams and companies have started to have issues keeping up.
Building and operating ML products started putting a lot of pressure on the data and ML engineering teams and where’s there’s pain there’s also opportunity!
More and more people started seeing opportunities for bringing new products to the market, promising to turn every company out there with any data, into an AI driven organization.
And just like this, we reached to the state of the industry you can see below.

MLOps category as included in MAD 2023
Keep in mind that the above landscape includes only companies labeled as “MLOps” and there are overlaps with other categories in the ML category of MAD 2023.
43 vendors, around $1B in investments without accounting for public companies like Google and AWS investing in the space.
What are all these companies offering? Let’s see!
What is inside an MLOps platform?
The MLOps vendors can be split among a number of product categories.
- Deployment & Serving of models, i.e. OctoML
- Model Quality and Monitoring, i.e. Weights & Biases
- Model training, i.e. AWS Sagemaker
- Feature Stores, i.e. Tecton
It’s important to mention here that the above categories are supplementary in many cases, for example if you use a Feature Store, you also need a service for model training.
If you pay attention to the product categories above, you will notice that there is nothing particularly unique about them in the grand scheme of things.
What do I mean by that:
Deployment and serving of models → This is a common operation found in both data engineering and software engineering. People have been deploying pipelines or even better, deploying applications of various complexity way before ML was a thing.
Model quality and Monitoring → This is a unique problem to ML. The way you monitor a model for quality is not the same as you do with a software project or a data pipeline. But this is only part of the quality problem as we will see later.
Model training → This is unique to ML but building models is nothing new, the question is what has changed in the past five years that requires a completely different paradigm in doing it?
Feature stores → This is one of the most interesting products of MLOps, for the uninitiated the first thing that comes to mind is some kind of specialized data base but feature stores are actually more than that. They are a complete data infrastructure architecture that is proposed and attempted to be productized. How different it is from the classic data infrastructure architectures? We will see.
Let’s see how each one of the above categories overlap (or not) with Data Engineering and what that means.
Deployment & Serving of Models
This is one of the most interesting aspects of MLOps in my opinion. Mainly because this is the part where the outcome of the work an ML Engineer does gets to the point where concrete value can be generated out of it.
A recommender can serve recommendations to users and fraud detection can be applied in real time.
But what is interesting here is that this process doesn’t have much to do with ML, the engineering problems are more related to product engineering.
We can think of a model as a function that requires some input and generates some output. To deliver value with this function we need a way to add it as part of the product experience we are delivering.
In engineering terms that means that we have to wrap the model as a service with a clean API that will be exposed to the product engineers.
Then we need to deploy this service in a scalable and predictable way, just like we do with any other service for our product.
After that we need to operate the service and ensure that it is provisioned the resources needed based on demand.
We also need to monitor the service for problems and be able to fix them as soon as possible.
Finally, we want to have some kind of continuous deployment - integration process to deploy updates to the service. Just like we do with any other service of our product.
As we can see, the above process is almost identical to managing the release cycle of any other software component out there while it’s primarily the product engineering involved as a stakeholder.
After all they have to ensure that the new functionality the model provides is integrated in the right way to the product without disrupting its operations.
There’s one specific need that is imposed to the engineering and ops teams because of having to work with ML models and this is related to monitoring the performance of the model itself but we will talk more about this later.
The question here is, if integrating a model to our product doesn’t differ than any other feature we release about the product, in terms of the release and platform engineering and operations, why do we need a whole new category of products?
My opinion here is that the industry is trying to solve the unique challenges of turning models into services by building complete new platforms, but this is less than optimal.
The true need here is developer tooling that will enrich the existing and proven platforms and methodologies for releasing and operating software at scale for the case of doing that with ML models as the foundational software artifact.
We don’t need MLOps engineers, we need tools that will allow ML Engineers to package their work in a way that the platform and release engineers will be able to consume and produce the artifacts needed for the product engineers to integrate into the product.
A recurrent pattern I see is an attempt from vendors who are trying to become category creators to define a new type of engineer.
In most cases, this is a crossover between existing roles, i.e. analytics engineer where you have someone who’s primarily an analyst but also does some part of the data engineering work, e.g. creates pipelines.
This is probably a smart marketing move but the world doesn’t work like that. New roles emerge and cannot be forced by a vendor.
Why we would like ML Engineers to assume responsibilities of a release or platform engineer? Why we would like the former to be introduced to a completely new category of tools that sounds alien to their practice?
Separation of concerns is a good thing both in software architecture and in organizational design.
Model Quality and Monitoring
This is where things are getting really interesting. quality assurance, control and monitoring is a huge topic in software engineering. In a way and with a bit of exaggeration, these are the elements that turn software engineering into… engineering.
There are many best practices and mature platforms for software quality related tasks. The problem is, that ML models can easily challenge these.
You might have heard that quality in data infrastructure is hard and it is. It’s not just the software that we have to monitor for quality, it’s also the data. And data is a different beast when it comes to applying quality concepts.
in ML the situation is even worse. You pretty much have a black box system generated and you need to monitor its performance by just observing its outputs based on the inputs it gets in production.
Because of this, Model quality and monitoring is usually mentioned together with terms like model drift. Where the model is monitored in terms of its “predictive” performance over time and if it drops under a threshold, we know that we need to retrain it with fresh data.
Which makes sense, right? As our product changes and our customers behaviors change, the model needs to get retrained to consider these changes.
I have two main arguments here.
The first is, how different is the observability of model quality metrics like drift different to any product related monitoring? In product we keep monitoring the performance of our features, do people engage with them in the way we expect? If something changed and engagement dropped, we should address that, right?
These are all part of what is usually referred as experimentation infrastructure for product and big part of it requires the right data infrastructure and data engineering to exist.
No matter how unique ML models are, at the end we are going to be observing a service - feature on how it performs interacting with our users and based on the data we collect, figure out if action is needed.
My feeling is that there’s a lot of overlap here between the ML observability and the data infra - engineering foundations that the organization is building for product experimentation.
My other argument is about data quality in general. ML models are built on top of data, their quality is a direct reflection of the quality of data used to build them.
This is a serious problem that data engineering is constantly fighting with and I can’t see how the replication of this process is helping in any way to solve the problem.
Data engineers are the people who are monitoring the data from its capture to the point where the ML engineer can use it. They have access to the whole supply chain of data and they can monitor and add controls at any point of that chain.
Adding another platform that is overlapping with both the data engineering and product engineering quality controls is not going to solve the problem and in the worst case it might make it even worse.
Again, the solution here is engineering tooling to enrich the existing architectures and solutions. Finding out what quality for data entails and equip the people who’s job is to ensure data and product quality to extend their reach into the ML models too.
Model Training
This is a short one to be honest. Model Training has more to do with Cloud Computing than anything else and in my opinion this is the space where the big cloud providers are mainly delivering value today. The main reason being the need for hardware to exist to do the actual training.
But in the general case, model training is nothing more than a data pipeline. Data is read from a number of sources and gets transformed through the application of a training algorithm. It doesn’t matter that much if this going to happen in the CPU or the GPU.
This is the bread and butter of Data Engineering, the tooling exists already and the main differentiation that I see here is the cloud compute abstraction where we are talking about a completely different category of infrastructure anyway.
Model training at scale should be part of the data engineering discipline as they have the tooling already, they have the responsibility for the SLAs on the data needed and they can control that release lifecycle much better.
Do the ML people bother with these operations? I can’t see why to be honest. I believe they would prefer to spend more time in building new models than dealing with operations for data crunching at scale.
I’m getting boring at this point but again, we don’t need new platforms. We just need to give the right tooling to DEs to communicate effectively with both ML and production engineers and add model training as another step in their ETL pipelines.
Feature Stores
I left Feature Stores for the end on purpose as they are a great example of the overlap with data engineering while their popularity is a great indication that something is not right with the current state of data infrastructure.
 The above is a feature store architecture as presented by Tecton, one of the first and most popular feature store vendors.
The above is a feature store architecture as presented by Tecton, one of the first and most popular feature store vendors.
Looking at that we see that we have:
- Stream data sources
- Batch data sources
- Transformations
- Storage
- Serving
- Model serving and training
Feature stores are similar to a typical data infrastructure architecture used by companies that require both streaming and batch processing capabilities. However, they specialize in supporting machine learning features by serving only one type of data consumer - the ML model.
Vendors have packaged the feature store architecture into products, which has caused some confusion. Some may question the need for another Spark or Flink cluster for real-time feature generation, especially if they are already using those tools for ETL jobs. However, feature stores are useful because they describe what needs to be added to existing data infrastructure to effectively productize machine learning.
As a product, feature stores should focus on building tooling and practices for data, ML, and product engineers to work together more effectively. Any additional overhead and complexity should be carefully evaluated to ensure that the benefits of using a feature store outweigh the costs.
Vendors should focus on providing useful tooling to support this, rather than duplicating existing data infrastructure.
Final Thoughts
I hope that by reading this essay you didn’t feel like I’m trying to dismiss MLOps because I’m not.
I believe that ML and its productization is important and will become even more important in the future and for this to happen the right tooling is needed.
But it’s time for the MLOps industry to mature and understand who the right audience is, what the problems are and bring the next iteration of solutions in the market.
Money and time was spent and lessons should have been learned. I can’t wait to see what the next iteration of these products will be.
There’s a lot of opportunity ahead!