Guide to SQL Dates with DuckDB.
Working with Dates in SQL, with examples in DuckDB.
For more 🚀
Check what I'm currently working on at Typedef.ai
A pragmatic guide on working with dates in SQL using DuckDB
Ok so we talked on how SQL deals with Dates and there’s a rich arsenal of tools to help us do whatever we want with time information in SQL.
But, working with dates is still a pain.
You might think that the technology is just not there but I would argue that it’s not a technical issue but more of a human issue plus the fact that time is just a hard concept.
Interpreting time is a messy business.
There are different ways to do it and there’s no way that someone can figure this out just by observing syntax.
For example consider the following date:
"2023-01-02"
What’s the right date format?
"yyyy-mm-dd" or "yyyy-dd-mm"
Both the above formats can syntactically express the above date but only one is right and to know which one, we either need more samples or we need someone to explicitly tell us what the format is.
This is just a tiny example that people from Europe moving to the US might have encountered in their every day lives, even without having to write code to parse dates.
Computers are simple
They are and they have a very elegant way of representing time.
The most common way to do it is by using an integer that represents time passed from a specific starting date.
The most common example of this approach is the Unix Time Stamp which tracks time as a running total of seconds, the count starts at the Unix Epoch on January 1st, 1970 at UTC.
You might wonder about how we count time before that, well, computers can represent negative numbers, right?
Assuming all time stamps are in UTC, representing dates like this is a very elegant way.
Applying operations on dates becomes as easy as applying operations on integers, e.g. addition and substraction.
Of course it wouldn’t be fan if everything was perfect.
So, we still have to ensure that time stamps are aligned on the timezone but this is relatively easy as we just have to offset a specific number to convert any timezone to UTC or any other.
Humans have agreed on something called UTC offset, where the timezone contains also the offset from UTC.
For example:
PT is the Pacific Time Zone. We have PST (Pacific Standard Time) and PDT (Pacific Daylight Time) with:
PST: UTC-08:00
PDT: UTC-07:00
As you can see from the above, we can easily get a UTC from a PST time by adding -8 hours and from a PDT by adding -7 hours.
As long as there’s syntactical information about the timezone in the date, it’s easy to work with it. we just need an index with all the timezone offsets and the timezones they correspond to it.
But as you can see, even working with just the timezone information can get tricky, what if there’s no explicit information about the timezone in the date we got?
Computers are simple as we said and that means that they don’t assume things on the other hand humans love implicit information.
And again, this is where things get hard with dates.
Serializations are not that simple though
Let’s get a bit more practical now and consider how information is exchanged between machines on the Internet.
We will consider the following formats:
- JSON
- CSV
- Protocol Buffers
JSON is the defacto format for exchanging data between web services.
CSV is probably the oldest human readable format and despite it’s age and issues, it’s still there.
Protocol Buffers is the defacto format for gRPC and related microservices.
For the above reasons, we can assume that anyone working in tech will have to work with them sooner or later.
(You can’t escape!)
Let’s see how each format represents date and time information.
JSON
How does JSON represent dates and times? Is there a datatype used?
The answer is: It doesn’t handle dates and there’s no datatype similar to what SQL has.
Dates and times are strings or integers if someone decides to store it as a timestamp but there’s no way to tell by validating the JSON doc if a key-value pair is representing a date or not. You need a human for that.
CSV
CSV also does not have a date or time type. Actually it doesn’t have types at all.
At least with JSON a numerical field will always have a number.
In CSV you can have a column - field that has mixed values and there’s no way to guarantee that this will not happen.
Protocol Buffers
Protobuf has support for timestamp types. It only supports a timestamp type, represented as a seconds and fractions of seconds at nanosecond resoltuion in UTC Epoch time (remember Unix Epoch?).
Obviously the support Protocol Buffers has when it comes to representing time is much more limited than something like SQL and for a good reason.
Protocol Buffers care only about computer communication, its design is not driven by the need to render dates and times to end users in every possible way.
Also, by limiting the ways that time can be represented, they can perform a lot of optimizations on how the information is serialized on the wire.
Something that is super important for protocols like that.
So what did we learn here?
Support for date types varies from protocol to protocol and depending on where the data comes from, an engineer will pretty much have to deal with every possible scenario.
So, how can we work with dates and time without shooting ourselves in the foot?
Some Examples with DuckDB
Let’s see some examples using DuckDB.
Consider the following CSV data:
| user_id | Event | Timestamp |
|---|---|---|
| 1 | click | 2023-02-28T21:07:13+00:00 |
| 2 | load_page | 2023-02-28T21:08:13+00:00 |
| 3 | load_page | 2023-02-28T21:09:13+00:00 |
| 4 | click | 2023-02-28T21:10:13+00:00 |
The above timestamp is represented in RFC3339 format.
Let’s see how we can parse this into SQL types using DuckDB.
DuckDB has great CSV parsing support. Assuming our csv file is named events.csv we execute the following command.
create view events as select * from read_csv_auto('events.csv');
select * from events;
and we get the following results:
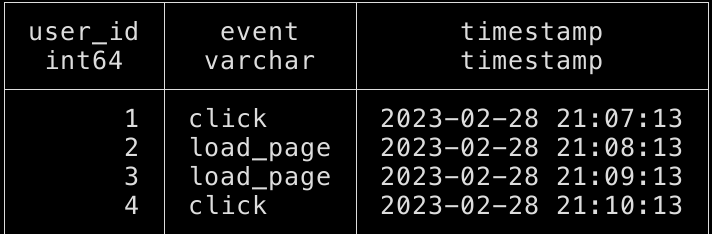
what is amazing is that DuckDB managed to guess the timestamp type and import it as timestamp directly!!
That’s because of the amazing work the DuckDB folks have done in delivering the best possible experience but also because we chose to use a standard like RFC3339 for representing dates.
Now we can move on and keep working with our data.
Now let’s see how powerfull DuckDB is in infering date formats. To do that, let’s change the date from 2023-02-28 to 2023-02-02.
The reason we want to try this is because in the first case, it’s easier to infer the format as we have only 12 months so the 28th should be a day.
Interestingly enough, DuckDB still infers the date format and creates a timestamp column!
Just try it using the same code as previously and you will see.
Finally, if we completely remove the time from the data, DuckDB will infer and use the data type Date instead of Datetime.
So, DuckDB is doing a great job in helping us work with date time data!
Let’s update our previous table and add a column that has a Unix Timestamp too.
| user_id | Event | Timestamp | unix_time |
|---|---|---|---|
| 1 | click | 2023-02-28T21:07:13+00:00 | 1677647233 |
| 2 | load_page | 2023-02-28T21:08:13+00:00 | 1677647293 |
| 3 | load_page | 2023-02-28T21:09:13+00:00 | 1677647353 |
| 4 | click | 2023-02-28T21:10:13+00:00 | 1677647413 |
D create view events_time as select * from read_csv_auto('events_time.csv');
D select * from events_time;
and the results we get are:
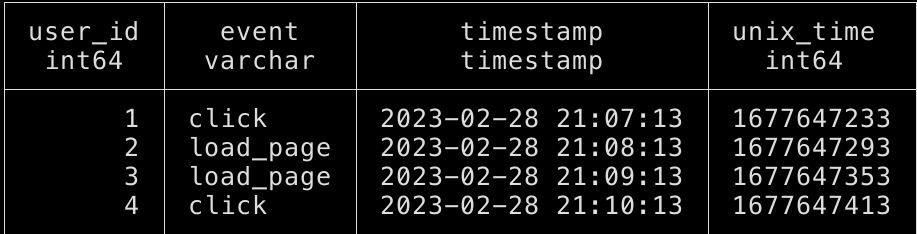
As you can see, DuckDB doesn’t know that unix_time is a timestamp, it registers the data type for this column as int64 which is what should be expected.
Many times we will just have timestamps being shared and not dates, how do we deal with that?
We just need to let DuckDB know what the data we are dealing with is.
In this case we know we are dealing with Unix timestamps and DuckDB has a number of utility functions to help us, more specifically we will look into the epoch_ms function.
Let’s execute the following SQL statement:
select user_id, event, timestamp, epoch_ms(unix_time) as unix_time from events_time;
The result we are getting is:
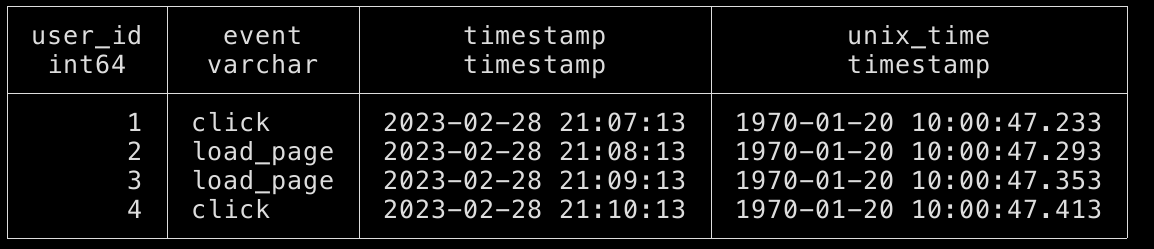
Which is obviously wrong, actually the timestamp and unix_time columns should match and there’s a huge difference between events happening in 2023 and 1970.
What went wrong? Remember the Unix Timestamp definition, it’s measured in seconds from the Unix Epoch but the signature of our function is epoch_ms which expects milliseconds.
Let’s try again with a slightly different query:
select user_id, event, timestamp, epoch_ms(unix_time * 1000) as unix_time from events_time;
Now the results look like:
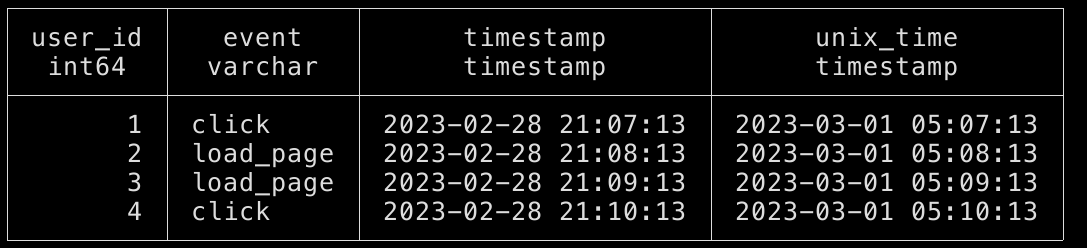
Better but still doesn’t look right. What’s going on here? Let’s try something to see if we can figure out what the issue is. Consider the following query.
select timestamp - epoch_ms(unix_time * 1000) from events_time;
The results will look like this:
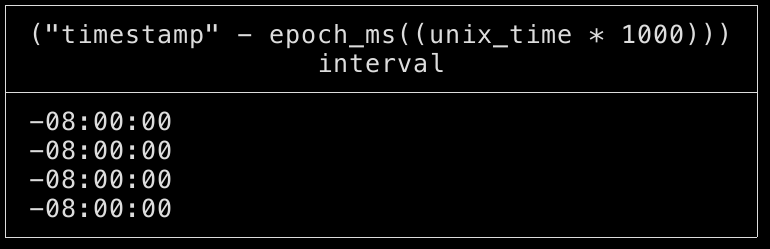
There’s something interesting here, the different is standard between the two timestamp columns and it also happens that the difference is equal to the difference between the timezone I live at (Pacific Time) and UTC.
So, the reason there’s a discrepancy between the two columns is because of the different timezones used and if we would like to be consistent, we should take into account the timezone in both cases.
Consistent semantics around time is one of the most important best practices when dealing with time in databases.
DuckDB has recently added support for working with JSON documents too. You should give it a try and repeat the above examples using JSON instead of CSV and see what the differences might be, if any.
Lessons Learned
Consistent Semantics
Consistency is key!
Keep it consistent, that’s the best advice when it comes to working with dates. Stick with a format and make sure that everyone follows that.
Now, that’s easier said than done, after all we will always have bugs and make errors. Even when there’s strict concensus on how to represent something.
First load, then deal with the data
First load your data into your database and then try to figure out if issues exist or not and how to deal with them.
That doesn’t mean that you should load the data into production tables though. On the contrary, load the data using temporary dev tables and then merge with production when you are sure on the data format.
Why do that? Because the last thing you want to do is to fail a whole pipeline because one date is malformed. To summarize.
Separate ingestion and loading logic on your data pipelines. First load into a temp table, then validate and then merge with production tables.
Ingestion takes time, especially with big workloads and a lot of that goes into IO and converting from one format to the other. You don’t want to waste resources doing all that because of syntactic issues that can be solved.
Separate Storage from Presentation
Because you will be sharing date and time information with humans, it doesn’t mean that you should store the data in the same format that a human expects.
Instead, stick to timestamps, assuming a standard timezone (most probably UTC) and whenever data has to be presented to the user, let the client figure out the best way to present the information.
By doing that, you ensure clear semantics across all your storage and at the same time maximize flexibility in terms of presenting the information to the consumer.
Learn to trust your database
Don’t try to re-invent the wheel, no matter what issue you have with your data, when it comes to dates there’s definitely someone who had to deal with the same in the past.
This knowledge has been integrated into query engines and databases and there are plenty of tools and best practices to follow.
Useful Links & References
Online Unix Timestamp Converter
Check what I'm currently working on at Typedef.ai